It’s been a while, but a new version is finally here with 0.2.8. This is technically a minor update to 0.2.7, but since I decided to make a new one before announcing 0.2.7 widely, this is really the new major release. Special thanks to sethk who provided some useful bug fixes!
Please download it and tell me what doesn’t work!
This release includes an awful lot of bugfixes, listed in the official release notes above; the most important thing is that many things that were broken now work, and that many models that couldn’t be loaded for one reason or another now can. The really interesting things are…
New Features
There’s a lot of them; all minor stuff, but all things that annoyed me and maybe you for years now.
Optional items
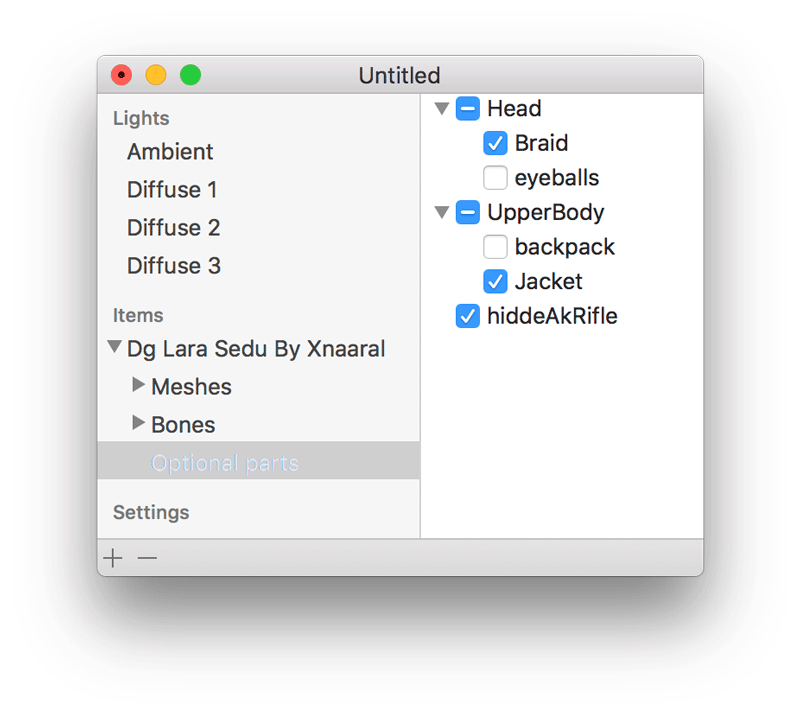
This has been a long-standing annoyance: Many newer models come with “Optional” parts that can be turned on or off via a menu in XPS. This menu didn’t exist in GLLara. You could turn these parts on and off manually, via the meshes, but finding out which ones needed to be set how was error-prone and annoying.
Now, models that have these optional parts get a new entry in the source list, which shows you a list where you can select or deselect them easily, and all the right meshes will be made visible or invisible. You can, of course, still adjust mesh visibility manually.
Bone UI updates
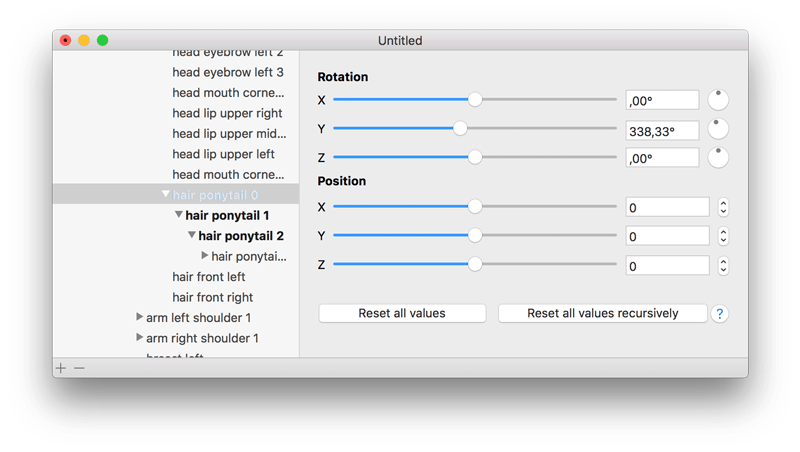
Bones that have had their values altered are now shown in bold, so you can quickly see which bones you edited and which are still missing. Very useful for fiddly bits with an awful lot of bones that want adjusting.
In addition to the normal “reset”, there is now also a “recursive reset”. This resets the bone and all its descendants to default values. You can use this e.g. when you are editing long hairs and then realised that you want something completely different, which requires setting all bones back to normal first.
Image planes
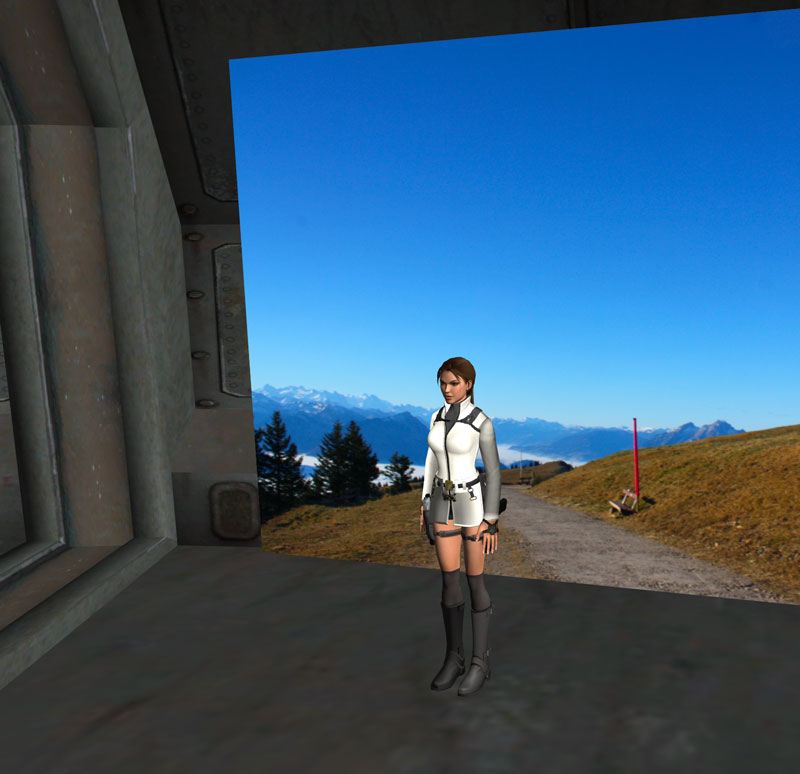
Images can now be loaded and placed into a scene as a possible, resizable flat plane. This can be used to add special effects, place pictures or similar very quickly. This supports all formats that GLLara supports for textures in general, meaning everything that Preview can open and also most .DDS files.
Adding models via drag and drop
Models and image planes can be added to a scene by dragging the file in finder and dropping it on the document or render window. This makes trying out a lot of new models a lot easier.
Show model files in Finder

This new menu item allows you to open the folder a selected model is in in Finder. This makes it a bit quicker to find things like readme files or alternate texture sets that may be included.
That’s it for now. There’ll be more updates in the future, but as always, there is zero guarantee on the time frame for this. I’m also thinking about changing the version numbering scheme. At the current pace we’ll reach 0.3 some time in 2030 and 1.0 shortly after the sun burns out. That’s useless, so I’m thinking the next major release will either be 0.3 or 1.0, regardless of content.
I decided to try loading some files with GLLara, found they didn’t work, and set to fixing it. That led to fixing stuff, changing approaches, shaving a proverbial yak… but now the first beta of version 0.2.6 is available. Give it a try!
The fundamental change here is that more different shaders available in XPS are now supported here as well. This means some (not all) models that didn’t work before (some or most parts didn’t show up) will work now. XNALara and XPS call these shaders “render groups”; of these, numbers 38 up to 43 are now supported. 34 and 35 are disallowed, and anything below 33 was already supported, so only 36 and 37 are missing now. I’m not sure if I’ll include them before the final release for 0.2.6 or put that in a different version.
To support so many new shaders quickly, I did something I had been planning for a long time and rearranged the shaders. Previously, every shader for every group was hand-coded (actually for every other render group; two render groups are typically the same, but one supports blending and one does not). That meant a lot of stuff was duplicated, and sometimes there were little bugs that I had fixed in half the shaders but not the others.
Now, there’s one shader, and for every render group I can configure which features it uses and which one it does. That way all bug fixes happen in one place, and I can add new shaders very quickly. For some of them, I didn’t even need to add any new code; they were just a new combination of existing features that I had to turn on.
Along the way I discovered a number of bugs in shaders that mean some things will look different from before now. Most importantly, the ambient color was sometimes ignored. Now it isn’t, but that means the default value is too bright. If everything in your scene looks gray, simply check the ambient color and turn it to black or very dark gray. I’ll probably change the default for this for the final version.
Such a big change means a lot of things may be broken, of course. If you have any examples where the same scene (or ideally just the same model) looks different in 0.2.6 beta 1 and 0.2.5, besides the gray thing, please let me know!. The same goes for any other issues as well, of course.
It took long enough, but here is the full release of 0.2.5, a.k.a. the version that fixes all known issues that appeared since 0.2.1, about three years ago.
Please download it and tell me what doesn’t work!
All the changes
This seems like a good time to go back to the basics and list all the changes since 0.2.2, the last version that was more or less widespread:
- The app runs on OS X 10.11 (previously there were weird graphics issues here).
- A multitude of bugs that only appeared on Intel cards are fixed.
- German localization works again.
- Setting parameters for single meshes was slow and wonky; for a lot of meshes, it was almost impossible. This is fixed now.
- A crash when changing shaders is fixed.
- Some XPS files that could not be loaded before now work.
- Some shaders didn’t work at all or didn’t work properly.
- Disabling of meshes did not work for a while.
- RAM usage was optimized, so the app now uses far less resources.
- Drawing was optimized, which should increase frame rate a little bit.
- Non-working Sparkle installation was removed (a new one may be added later).
- A lot of cleanup behind the scenes to make code shorter and easier to read.
- Skeleton drawing did not work for a while.
There’s also new features:
- You can now set anti-aliasing and anisotropic filtering from the settings.
- You can change whether a mesh is treated as transparent or not. Note that it won’t show up as transparent unless it also has a transparent diffuse texture.
Both are mostly meant for playing around.
This is a test release for now, but should be pretty close to the main release of 0.2.5 unless anybody complains soon. This release fixes the problems on OS X 10.11 “El Capitan”.
Please download it and tell me what doesn’t work!
What happened to Beta 2?
It’s out there, under releases, I just forgot to make a blog post for it. But I have already talked about the biggest improvements anyway. The big take-away is that the german localization works again and that a lot of things that were weird, slow or crashy, or all three, now work flawlessly.
The changes
The big one is “El Capitan” compatibility, which was all down to something I could fix in a single line. The main problem was that depth test didn’t work, and also the clear color, which came all down to the wrong OpenGL context being set when I set up that state. Made for some interesting pictures, though:

The other big change is user settings. Under “GLLara/Preferences”, there is now a preference window that allows you to play with render settings. You can now play with anisotropy:
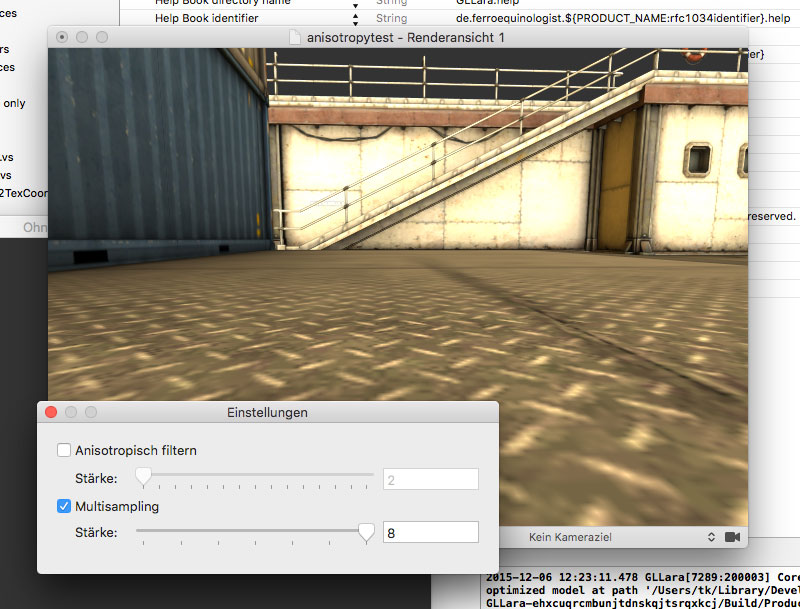
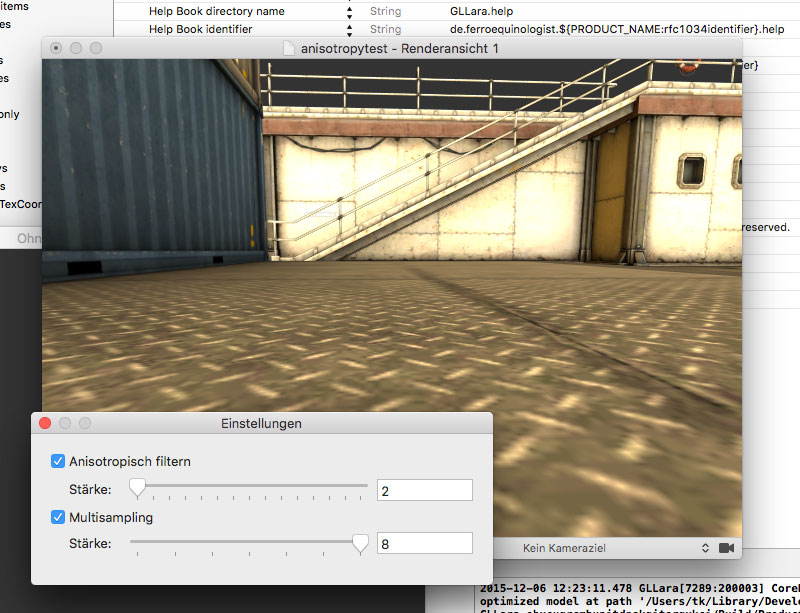
And also with anti-aliasing, also known as multi-sampling.
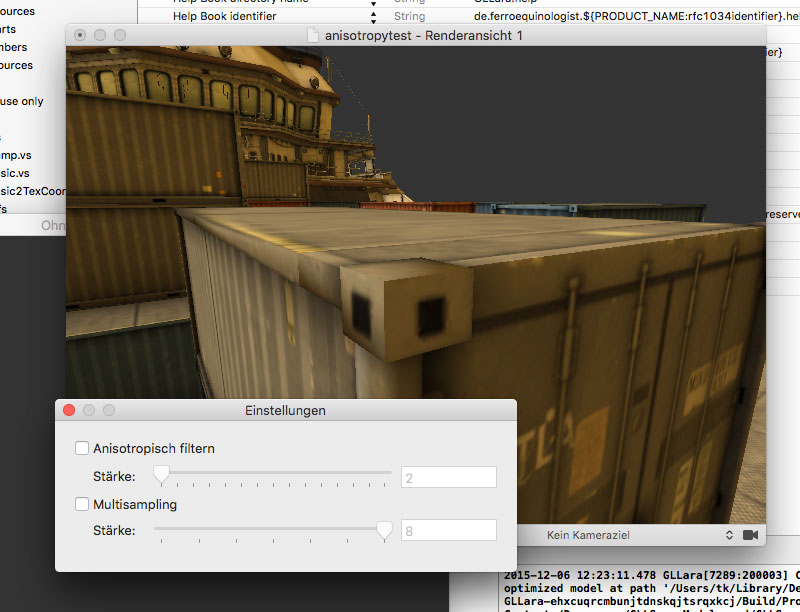
Note: Anti-aliasing is not supported for rendering to a picture file. Just render at a larger size and calculate it down with Photoshop, that should do the trick. Also, don’t be surprised if you don’t see the difference between 2x MSAA and 8x MSAA. It’s incredibly subtle. If you have a Mac with retina display, anti-aliasing may be entirely pointless.
Does anyone still remember the good old days of the mid-2000s? Back then Intel Macs were first a rumor, then a hot new thing (but you couldn’t drop support for PowerPC just yet). The iPod had just exploded and the iPhone was nothing but a persistent rumor - and only the authors of joke sites predicted that it would only have one button. And on the development side, we still thought the highly dynamic nature of Objective-C, and the things it enabled, were a feature, not a bug, and that there was value in having a small versatile language instead of one with a special case for every last thing, down to a guard-let-where-else construct to “make code easier to understand.” No I’m not annoyed with Swift at all…
Okay, I am, but I’m also somewhat unfair. The truth is most of that dynamic nature often hurt more than it helped, something that e.g. Brent Simmons knew way before Swift. And while you may disagree with him, he’s not someone you can just dismiss. For many problems, it was simply the wrong tool. Nobody ever used NSProxy. Higher Order Messaging was a giant mess, and for-in loops and blocks are better in every situation. People had realized that you shouldn’t type your variables as id without a very good reason long before I started programming. To a large degree, Swift is the logical conclusion of a development from theoretically interesting freedom to a strict, structured thing that actually lets you get work done, and that development started long before.
GLLara doesn’t do anything crazy with dynamic Objective-C, except for the one thing that did go mainstream, but that’s also maybe the most crazy of them all; the one Brent Simmons complained about in the post I linked to: Bindings and Key-Value Observing. Awesome technological achievements that make a lot of stuff very easy, but also things that will entangle your code flow to no end, cause all sorts of trouble and performance issue. It’s no surprise that some key elements of the system (the controller classes) never made it to iOS, and probably never will now.
The part that caused problems for me was always the meshes view in the settings window. It never worked reliably, because it had a lot of weird stuff to do: The tables don’t represent lists, but named placeholders, each of which edits the same attribute on all of the selected objects. Doing that with NSArrayController required a lot of hacking. Think +[NSString stringWithFormat:] to find key paths to bind to. This should scare you. There were also massive performance issues when selections got large, due to observers registering and deregistering.
The solution now is a bit roundabout, but works. Each binding now takes place through a special placeholder class. This placeholder class has a value property that can be bound to (we’re not monsters here, I keep using bindings for things where it makes sense). It also has a selection that it observes for changes. And it listens for DidUndo/DidRedo notifications.
Updating is simple: Go through selection, get the value for every object (using an accessor method that’s overriden in subclasses), if you get two different ones simply use the default multiple value marker. When a new value is set through the property, simply force it on all objects in the selection. The update is triggered by undo, redo and selection changes.
This means the new class only works if all mutations go through it or through undo/redo. Otherwise its value will be stale. Enforcing this requirement is easy, though, because there’s only one relevant UI element and not a lot of other options for the value to change.
The result: All the crashes when changing shaders are gone. Changing a color value for a thousand meshes works instantly. There are still a few minor things to adjust, but it seems like 0.2.6 should be ready for release some time this week and bring a lot of improvements here.